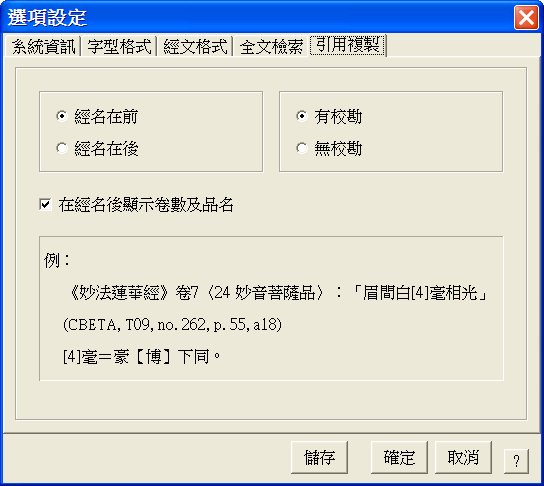
設定
|
CBReader 選單中的  下有六個選項:「工具列」、「選項設定」、「設定檢索範圍」、「設定外部連結」、「畫面重整」、「Language」(語言)。如下圖: 下有六個選項:「工具列」、「選項設定」、「設定檢索範圍」、「設定外部連結」、「畫面重整」、「Language」(語言)。如下圖:

|
工具列
有四個選項: ,內定為勾選。 ,內定為勾選。
以上選項決定 CBReader 面板如下各工具列的呈現與否。

選項設定
 如果「選項設定」中的經文格式有做任何的變更,必須要使用「畫面重整」才能呈現變更設定後的效果。 如果「選項設定」中的經文格式有做任何的變更,必須要使用「畫面重整」才能呈現變更設定後的效果。
 畫面重整 畫面重整
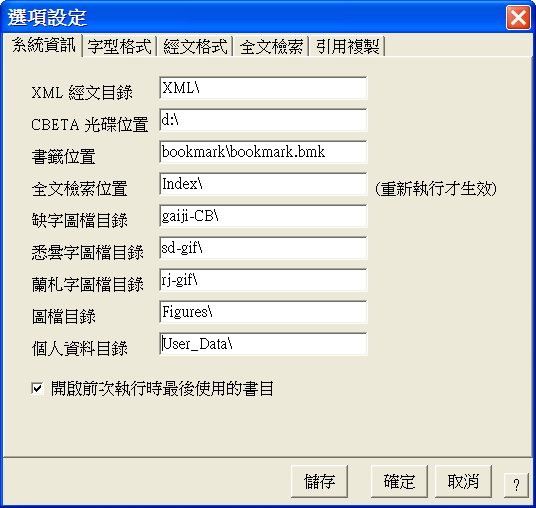
XML 經文位置:
預設位置是:XML\
這就是直接開啟經文時的讀取位置,如果使用者自行將 CBReader 或經文複製到硬碟時,請設定正確的目錄。
CBETA 光碟位置:
當使用者以「最小安裝」的方式安裝 CBETA 光碟時,會自動偵測所安裝光碟機的代號。
這種設計的主要目的是讓使用者可以將最新版的經文放在硬碟中,程式在讀取資料時,會先讀取「XML 經文位置」的經文,當找不到時,才會尋找光碟中的經文;當二者都找不到,就會秀出警告訊息了。
本程式在搜尋經文時,會先後搜尋二個目錄。
第一個是「XML經文位置」,若找不到經文,就會尋找「CBETA光碟位置」中預設的經文目錄。
書籤位置:
使用者書籤的檔案位置。此位置必需在硬碟中才能有效儲存。
全文檢索位置:
全文檢索的索引檔目錄,若此目錄無資料,程式會自動尋找光碟中的全文檢索預設目錄。
缺字、悉曇字、蘭札字、圖檔目錄:
各種圖檔的所在目錄。
個人資料目錄:
用來儲存檢索範圍檔、檢索結果檔....等個人的資料。
開啟前次執行時最後使用的書目:
若選擇此項目,則執行時會開啟前次執行時最後使用的書目,否則就是開啟預設的
CBETA 經錄。
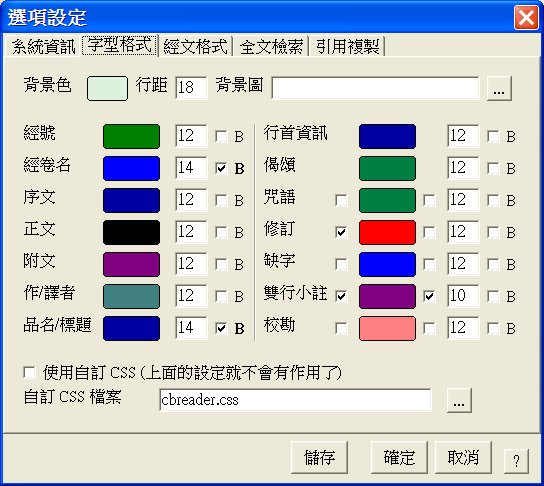
字型格式可設定各種文字的顏色、大小與是否為粗體。其中咒語、修訂、缺字、雙行小註及校勘可能因為會出現在各種格式中,故亦可選擇不特別指定顏色及字型大小。
使用者亦可自行設定背景色,背景圖與行距。
若使用者有能力編輯 CSS 檔,則可對格式有更完整的控制,使用自訂的 CSS 就會忽略字型格式的各種設定,CSS 內容則可參考程式目錄中的 cbreader.css。
|
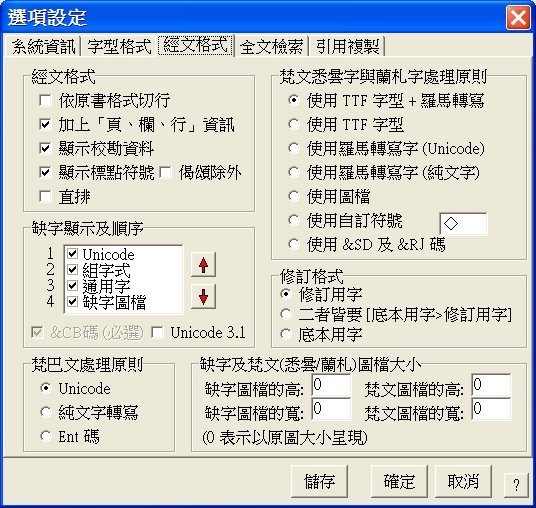
經文格式:
1.依原書格式切行:
可依大藏經原書編排的格式輸出。
2.加上「頁、欄、行」資訊:
若是依原書格式切行,則會在每一行輸出標準的行首資訊。反之,則只會在每一段落的開頭列出資訊。
3.顯示校勘資料:
可選擇是否在經文中呈現校勘。
4.顯示標點符號:
可選擇是否在經文中呈現標點符號。
4-1.偈頌除外:
為了偈頌整齊排列,可選擇不在偈頌中呈現標點符號。
5.直排:
可選擇以直排方式呈現經文。
請注意:「直排」是 V3.0 版之後才加入的選項,它是利用 IE 的直排功能,但在測試時發現它有許多功能沒有完整支援,故此選項建議僅供測試。
缺字顯示及順序:
使用者可以自訂缺字的呈現方式,並且依照個人需求決定次序。上圖的範例中,會優先使用
Unicode , Unicode
沒有該缺字時,其次設定選用通用字,依此類推。如果全部都沒有選擇或支援,則至少會輸出
&CB 碼,這是 CBETA
所製定的缺字編碼 (流水碼)。
如果您的系統有支援 Unicode 3.1,則可以勾選 "Unicode 3.1" 的選項。
如果您的系統僅支援 Unicode 2.0,則請勿勾選 "Unicode 3.1" 的選項,否則會有看不到某些經文用字的情況。
梵巴文處理原則:
梵文及巴利文的呈現原則。
- Unicode:例如
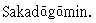
- 純文字轉寫:例如
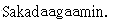
- Ent 碼:例如
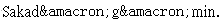
悉曇字處理原則:
可使用悉曇字型、羅馬轉寫字(unicode
或純文字)、悉曇字圖檔、自訂符號或
&SD 碼。
- 使用 TTF 字型 + 羅馬轉寫:例如
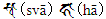
- 使用悉曇字型 (siddam.ttf):例如
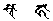
- 使用羅馬轉寫字 (Unicode):例如
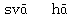
- 使用羅馬轉寫字 (純文字):例如

- 使用悉曇字圖檔:例如
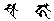
- 使用自訂符號:例如
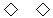
- 使用 &SD 碼:例如 &SD-B065;&SD-A6A9;
修訂格式:
可選擇只看 CBETA 「修訂用字」,「底本用字」,或是同時參考「修訂用字」與「底本用字」。
修訂格式是因為在處理電子佛典時,會發現一些疑為底本用字錯誤的情形,此時 CBETA 會參考上下文與其他藏經版本,在判斷為底本用字錯誤時,會針對經文予以修訂。
例如底本經文是「阿羅羅」,但根據上下文及其他版本,判斷其為「阿羅漢」之誤。
若使用者選擇「修訂用字」,則會看到「阿羅漢」。
若使用者選擇「底本用字」,則會看到「阿羅羅」。
若使用者選擇「二者皆要」,則會看到「阿羅[羅>漢]」。
(紅色為使用者選擇修訂文字呈現的顏色)
請注意:目前全文檢索只能檢索「修訂用字」,被修訂的底本用字無法被檢索到。以上例而言,使用者可以檢索到「阿羅漢」,但無法檢索「阿羅羅」。
缺字及悉曇字圖檔大小:
內定值為 0
,用來顯示原始圖檔大小,使用者可依習慣自行調整大小。
注意事項:
在上述的各項設定中,其中悉曇字型的文字及各種
Unicode 字體無法直接複製在純文字的環境中,僅能使用在某些可選擇字型支援的編輯器內,如:Word。
|
|
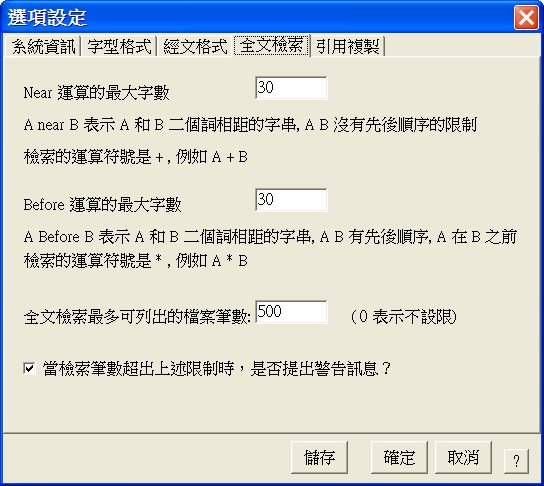
全文檢索除了單字與單詞檢索之外,尚有四種運算方式。
1.Near 運算:其使用符號為
+
示範:佛陀 +
阿難
其意為當一篇文章同時出現「佛陀」與「阿難」,這二個詞沒有先後順序的限制,但有距離的限制,只要距離小於在選項中的「Near
運算的最大字數」,即符合所要尋找的資料。
2.Before 運算:其使用符號為
*
示範:佛陀 *
阿難
其意為當一篇文章同時出現「佛陀」與「阿難」,而且「佛陀」要在「阿難」之前,並且二者的距離小於在選項中的「Before
運算的最大字數」,即符合所要尋找的資料。
3.And 運算:其使用符號為
&
示範:佛陀 &
阿難
其意為當一篇文章同時出現「佛陀」與「阿難」即可,沒有順序與距離的限制。
4.Or 運算:其使用符號為
,
示範:佛陀 ,
阿難
其意為當一篇文章同時出現「佛陀」或「阿難」即可,沒有順序與距離的限制。
5.Exclude 運算:其使用符號為 -
示範:舍利 - 舍利弗
其意為當一篇文章出現「舍利」,而且此詞並不是「舍利弗」,即符合所要尋找的資料。
注意事項:
- 可以使用 ( ) 來表示較高的運算次序。例:佛陀, (阿難 & 如來)。
- 可以使用萬用字元 ? 來表示任何一個字,例如檢索「蓮?色」,即可找到「蓮華色」,「蓮花色」.....等。
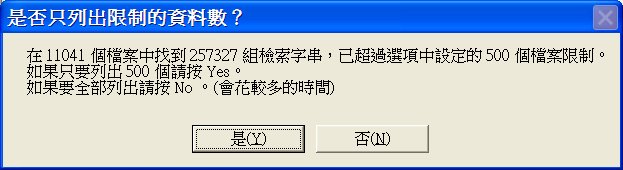
全文檢索最多可列出的檔案筆數:
若搜尋到的檔案數太多時,會造成呈現速度緩慢,而大量的檢索結果也不符合實際應用,故可以限制輸出的檔案數,以供使用者決定先行使用或改變檢索方式。
當檢索筆數超出上述限制時,是否提出警告訊息:
當檢索的結果超出上述的限制筆數時,可要求程式提出警告,並且在此時可以決定只輸出限制的檔案數或全部輸出。
|
設定檢索範圍 詳情請參考「全文檢索」中的「設定檢索範圍」說明。
畫面重整 詳情請參考「工具列」中的「畫面重整」說明。
Language (語言)
Language 下目前有六個選項:Chinese(Big5)(中文繁體)、Chinese(GB1 & GB2)(中文簡體)、English(英文)、Japanese(JP & JP1)(日文)。
語系檔的位置是在 CBReader\Language 目錄中,使用者可依個人的使用習慣新增語系或修改現有的語系檔,修改後只要再選擇主功能表中的語系設定,就可以立刻更新結果。
語系檔除了可以修改程式畫面上的文字之外,也可以設定執行中的各種訊息,亦可調整字體與字型大小。
新增的檔名必須以 cbr_ 為檔名開頭,且必需使用 ini 為副檔名,內容請參考 cbr_big5.ini 或 cbr_eng.ini 的內容,若您有新增其它的語系,歡迎寄給我們,讓我們放在網站上提供有需要的使用者下載。
Email 請寄至 service@cbeta.org
|