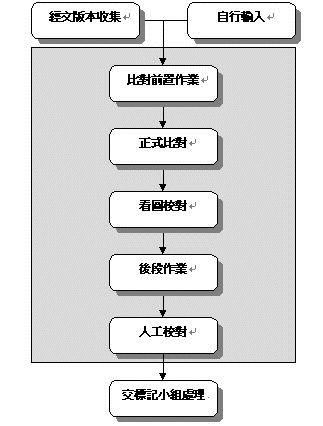
CBETA校對組作業流程簡圖
 |
檔案比對作業流程及相關要點
吳寶原
(以版本A、B兩相比對為例)
A.前置作業
1.檔案合併:
利用檔案合併程式,將小檔合併成大檔,以利文書編輯處理及後續比對作業的進行。
2.進行大正藏格式化:
利用一系列的大正藏格式化程式,將版本A予以格式化。
3.消除重大差異:
針對版本A、B兩者明顯差異,例如有無序文、注解以及卷末經卷名,以版本A為主來予以統一。
4.代碼及常見錯誤字串取代:
透過<大正藏字串取代表>,將版本A之「數字代碼」及「錯誤字串」轉換為一般組合字或正確字串。
5.統一缺字表示:
至此,版本A之缺字皆以一般組合字表示;而版本B之缺字或是以造字或另種組字式表示者,須整批替換成與版本A一致。
B.正式比對──FGFC
1.利用 FGFCSIGN.ALL 建立 FGFCSIGN.TXT,將欲忽略字元做好最佳設定。
2.以 FGFC 內定參數值 (MaxwordNum CompareNum = 100 2),加掛使用者自訂忽略字元,開始初步執行兩檔比對。
3.比對時因差異過多而導致中斷,則檢查為何差異過多,並予有效排除:
a.若因某一版本漏打或重複輸入,則予以增補或刪除。
b.若因版本文字本就有很大差異,則將 FGFC 參數值加大後再跑看看,或是將這差異過多部份做好記錄後截取出來個別處理。
4.若 FGFC 可以順利執行完畢,則統計其差異發生次數,並檢視所產生的三個檔案:
a.若出現大量規則性差異處,則經整理研判後,以字串取代方式處理。
b.若有密集的連續差異發生,則調整 FGFC 參數(建議 150 10 )重新執行。
5.經過以上處理,以最適當參數再次執行 FGFC ,並比較其差異發生次數是否較上次少;如果無法有效減少,則再回上一步驟檢討。
C.看圖校對
1.比對之後的差異檔,可以利用 SeeCheck 看圖校對程式來予以訂正。
2.建議:如果硬碟空間夠,可把所有圖檔拷到硬碟裡來作業。
3.對於簡單差異,SeeCheck的作業效率很高;但若差異範圍稍大,SeeCheck就不好玩了。所以,我們最好是先使用 SeeCheck 來解決佔最大多數的簡單差異,然後再以一般看書校對的方式來解決剩餘的少數大範圍差異。
D.最後的可能手續
1.依<大正藏內文格式>,將經名、品名、譯者名,以及各種長短偈頌等,排列整齊。
2.刪除經文當中不應存在的半形空白字元。技巧是利用漢書:
a.將連續兩個半形空白全部替代為一個全形空白。
b.搜尋經文當中是否尚存有半形空白?若有,逐個搜尋並判斷應否刪除。
3.透過字頻統計程式,查看對稱性符號是否相等,有沒有出現不該有的字元;若有發現,設法解決。
4.如果「錯誤語詞資料庫」及相關程式建立起來,則可以拿來檢查成品的可能潛在錯誤。
E.相關程式
1.檔案合併
Mergfil2───Tone
2.大正藏格式化系列程式
a.25tchk10──Tone
b.25tform6──Tone
c.25t-tst7──Tone
3.字串取代
a.Chng25t ──Tone (快速將規則性代碼取代為對應字串)
b.Convert ──Lyyen(不規則字串取代)
c.Convert ──Heaven(Perl程式)
4.檔案比對系列程式及訂正巨集
a.Fgfc ───Heaven
b.Fgfce ───Heaven
c.Fg3fc ───Heaven
5.看圖校對程式
SeeCheck───Heaven
6.字頻統計
a.Countwrd──Tone (全、半形皆可)
b.Convert ──Lyyen(特針對全形字)
c.Count ──Heaven(Perl程式)
F.漢書文書處理重要技巧
1.搜尋與取代:針對全文或標示區,以各種特殊條件來進行搜尋及取代。
2.標示、複製、搬移、覆蓋、刪除、填入
3.標示區存檔、加流水號、記錄及還原游標位置
4.排序:針對全文或標示區
5.巨集:以簡單巨集取代重複性動作